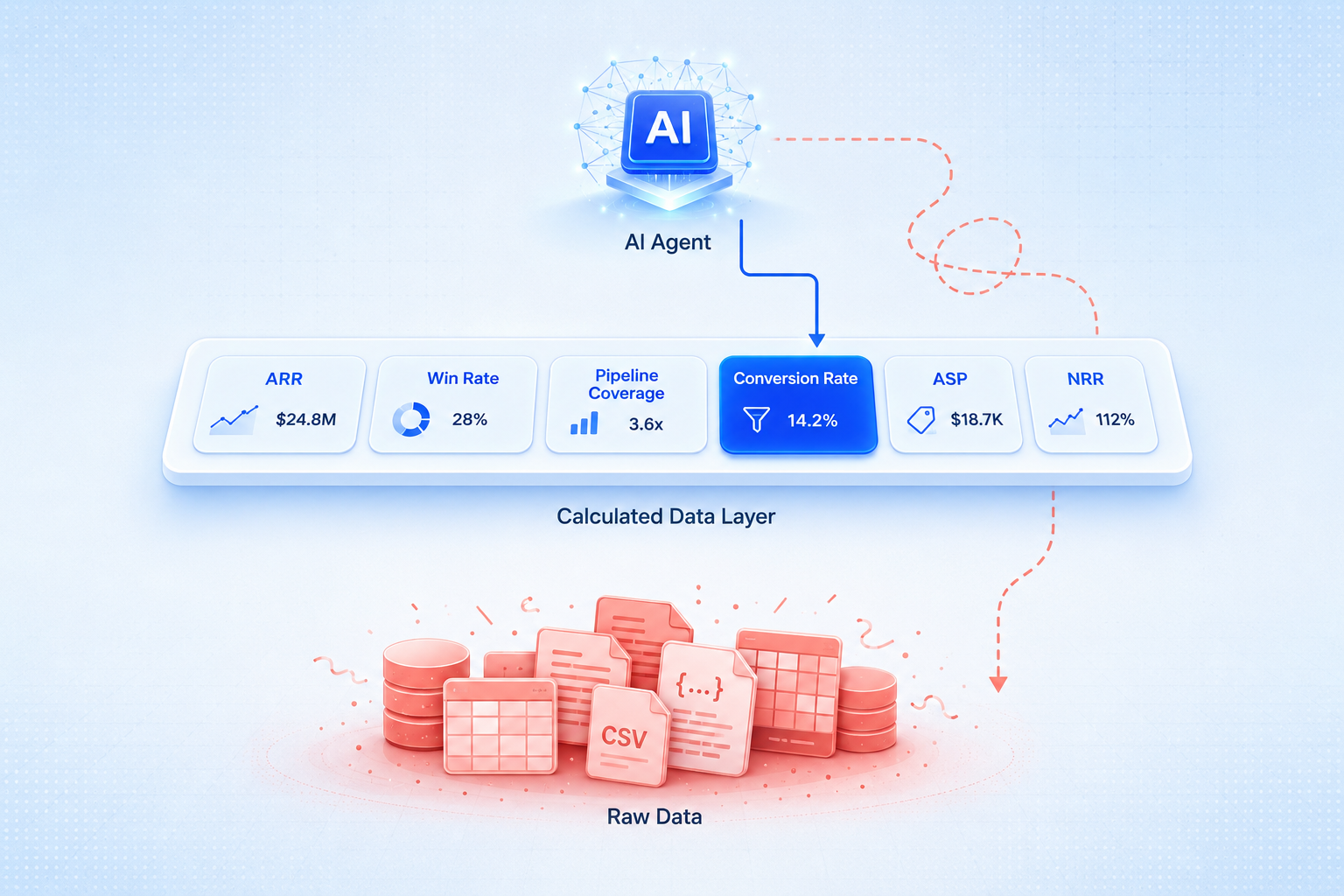
AI is quickly becoming a core part of how companies analyze data, answer business questions, and automate workflows. But as more organizations deploy AI agents and connect them to business systems, two concerns keep coming up:
How much will AI cost to run?
How do we prevent inaccurate or hallucinated answers?
Many teams focus on token usage first. They ask how much it costs to ask a question, run an agent, retrieve context, or process a workflow. Others worry about what happens when AI is connected to CRMs, data warehouses, spreadsheets, SaaS tools, and MCP servers without clear business definitions.
These concerns are connected.
When AI has to process raw, undefined, or inconsistent data, it needs more context, more reasoning, and more tokens. It also has more room to misunderstand the business meaning behind the data.
That is why companies need a calculated data layer.
The Problem With Giving AI Raw Business Data
Raw data is not the same as business-ready data.
A CRM may contain opportunity records, stage changes, close dates, rep assignments, and deal values. But that does not mean AI automatically knows how your company defines a sales cycle, conversion rate, pipeline coverage, or average selling price.
For example, if a user asks:
“What is our pipeline coverage by rep?”
AI may need to understand:
- Which opportunities count as pipeline
- Which stages should be included
- How quota is assigned
- Which time period matters
- Whether renewals, expansions, or test records should be excluded
- How your company defines coverage
Without those definitions, AI is forced to infer. That creates two problems: higher token usage and lower accuracy.
Why More Context Does Not Always Mean Better AI Answers
A common response to AI accuracy issues is to give the model more context. Companies expand the context window, connect more tools, add more documents, and retrieve more records.
But more information does not always produce better answers.
If the data is inconsistent or undefined, AI may retrieve a large amount of context and still fail to produce a trustworthy response. It may combine conflicting definitions, interpret metrics incorrectly, or produce a confident answer that does not match how the business actually operates.
This is especially risky for executive reporting, sales forecasting, marketing attribution, customer success metrics, and financial analysis.
AI does not just need more data. It needs better-defined data.
A larger context window doesn’t make AI a better analyst. Defined metrics do. More context window just gives AI more room to be confidently wrong about your business.
What Is Calculated Data?
Calculated data is data that has already been transformed into business-ready metrics using clear definitions, rules, and domain knowledge.
Examples include:
- Sales cycle length
- Conversion rate by stage
- Pipeline coverage by rep
- Average selling price by rep
- Win rate by segment
- Customer health score
- Renewal risk score
- Marketing-sourced pipeline
- Expansion potential
- Forecast accuracy
These are not just numbers. They represent how a company defines, measures, and evaluates performance.
A calculated data layer gives AI access to metrics that already include the company’s business logic.
Calculated Data Reduces AI Hallucinations
AI hallucinations often happen when the model is asked to answer questions without enough reliable grounding.
When business definitions are missing, AI has to guess. It may assume a standard definition that does not apply to your company. It may calculate a metric differently than your sales, marketing, finance, or customer success teams expect.
Calculated data reduces this risk because the answer is grounded in governed business logic.
Instead of asking AI to figure out what “pipeline coverage” means, the calculated data layer already defines it. AI retrieves the metric and explains it based on your company’s rules.
That makes responses more consistent, relevant, and trustworthy.
Hallucinations and runaway token bills are symptoms of the same disease — AI guessing at definitions you should already have nailed down…and then re-guessing and re-guessing again.
Calculated Data Reduces Token Usage
Token costs rise when AI has to retrieve, read, interpret, and calculate from large amounts of raw data.
For example, to answer a question about sales cycle trends, AI may need to process opportunity history, stage movement, timestamps, close dates, rep assignments, and filters.
With calculated data, much of that work is already done.
Instead of sending large volumes of raw records into the context window, AI can retrieve the final business-ready metric. This reduces the amount of context required and allows the model to focus on explanation, insight, and recommendations.
The result is a more efficient AI system.
Pre-Calculated vs. Calculated on the Fly
Calculated data can be created in two ways.
Pre-Calculated Data
Pre-calculated data is generated before the AI request. These metrics are stored in a knowledge base, semantic layer, data warehouse, or context layer.
This works well for recurring business questions such as:
- What is pipeline coverage last quarter?
- What was our average sales cycle?
- Which reps were below target?
- What was our conversion rate by stage?
- Where were our deals stuck?
Calculated on the Fly
Some metrics need to be calculated at the moment of the request. This is useful when the user asks a specific or unusual question.
For example:
“What was the average sales cycle for enterprise deals in the West region created after our pricing change?”
In this case, AI can trigger a governed calculation using approved definitions instead of inventing its own logic.
Calculated Data Becomes Part of the AI Knowledge Base
Many companies think of AI knowledge bases as documents, PDFs, policies, and help center articles. But business metrics should also be part of the knowledge base.
A calculated data layer gives AI a structured understanding of how the business works.
It captures domain knowledge from teams like:
Sales
Pipeline coverage, quota attainment, win rate, ASP, forecast risk
Marketing
Lead conversion, attribution, campaign ROI, sourced pipeline
Customer Success
Health scores, churn risk, renewal probability, expansion signals
Finance
Revenue performance, margin analysis, growth efficiency, budget variance
Operations
Capacity, productivity, cycle time, process efficiency
This turns company-specific business knowledge into reusable AI context.
Saving AI Answers for Historical Context
Another way to reduce token usage is to save AI-generated answers and retrieved results for future use.
Many business questions are repeated:
- “Which reps are at risk this quarter?”
- “What changed in pipeline this week?”
- “Why did conversion drop last month?”
- “Which customers need attention?”
If AI has to retrieve and recalculate everything each time, costs increase. But if previous answers, supporting metrics, and historical explanations are stored, AI can reuse that context or update it incrementally.
This creates an organizational memory layer.
Over time, AI becomes more efficient because it does not need to start from zero with every question.
Why Domain Knowledge Matters
A calculated data layer is only valuable if it reflects how the company actually operates.
That requires domain knowledge.
Sales teams define pipeline differently than finance teams. Marketing may look at attribution differently than revenue operations. Customer success may measure risk using product usage, support activity, renewal timing, and executive engagement.
Industry-specific metrics also matter.
A SaaS company, healthcare organization, financial services firm, manufacturer, or marketplace may all need different definitions, calculations, and KPIs.
Calculated data should reflect the business model, operating rhythm, and decision-making process of the organization.
The Future of AI Is Not Just More Data & Dashboards
The next phase of enterprise AI will not be won by companies that connect the most data sources.
It will be won by companies that provide AI with the most useful, governed, and business-aware context.
Raw data gives AI access.
Calculated data gives AI understanding.
When AI retrieves calculated metrics, it can answer in a way that is aligned with company definitions, business logic, and operational reality.
That means fewer hallucinations, lower token usage, faster answers, and better decisions.
Conclusion
AI costs and hallucinations are not just model problems. They are data architecture problems.
When AI has to work from raw data, it consumes more tokens and has more opportunities to misinterpret the business. But when AI is connected to a calculated data layer, it retrieves information that is already defined, governed, and relevant.
Calculated data helps AI understand the business the way the business understands itself.
For companies deploying AI agents, analytics copilots, or AI-powered decision systems, calculated data is not optional. It is the foundation for accurate, efficient, and trustworthy AI.
Frequently Asked Questions
Calculated data is business-ready data that has already been processed using defined rules, formulas, and company-specific logic. It helps AI retrieve accurate metrics instead of calculating everything from raw data.
Calculated data reduces token usage by limiting the amount of raw data AI needs to process. Instead of reading thousands of records to calculate a metric, AI can retrieve a pre-defined result and use fewer tokens to explain it.
Yes. Calculated data helps reduce hallucinations by grounding AI answers in approved business definitions. This prevents AI from guessing how a metric should be calculated.
Examples include sales cycle length, conversion rate by stage, pipeline coverage by rep, average selling price, win rate, customer health score, renewal risk, and marketing-sourced pipeline.
Calculated data can be part of a semantic layer, knowledge base, or AI context layer. The goal is to give AI access to governed business metrics and definitions.
AI agents often need to answer complex business questions or take action based on company data. Calculated data gives agents reliable context so they can produce more accurate and relevant outputs.
Both approaches are useful. Common metrics should often be pre-calculated, while more specific or custom questions may require governed calculations on demand.
Calculated data ensures AI answers are based on consistent definitions and business logic. This helps teams make decisions using metrics they can trust.


